
Writing scalable code is one of the most valuable skills a developer can build, yet it remains one of the least formally taught. You might write software that works perfectly for a hundred users, only to watch it buckle under ten thousand. Scalability isn't just about handling more traffic; it's about building systems that grow gracefully without requiring complete rewrites.
This practical guide walks you through proven code optimization techniques, clean code principles, and refactoring tips that help your software perform well at any scale. Whether you're building microservices, APIs, or monolithic applications, these steps apply across languages and frameworks.
The difference between code that survives and code that collapses often comes down to the architectural and design decisions made early in development. Let's break down exactly how to get those decisions right.
Key Takeaways
- Scalable code starts with modular architecture that separates concerns into independent components.
- Choosing the right data structures impacts performance more than most micro-optimizations.
- Horizontal scaling requires stateless design patterns from the beginning of your project.
- Profiling before optimizing prevents wasted effort on code that isn't the actual bottleneck.
- Consistent refactoring habits keep technical debt from compounding into scalability blockers.
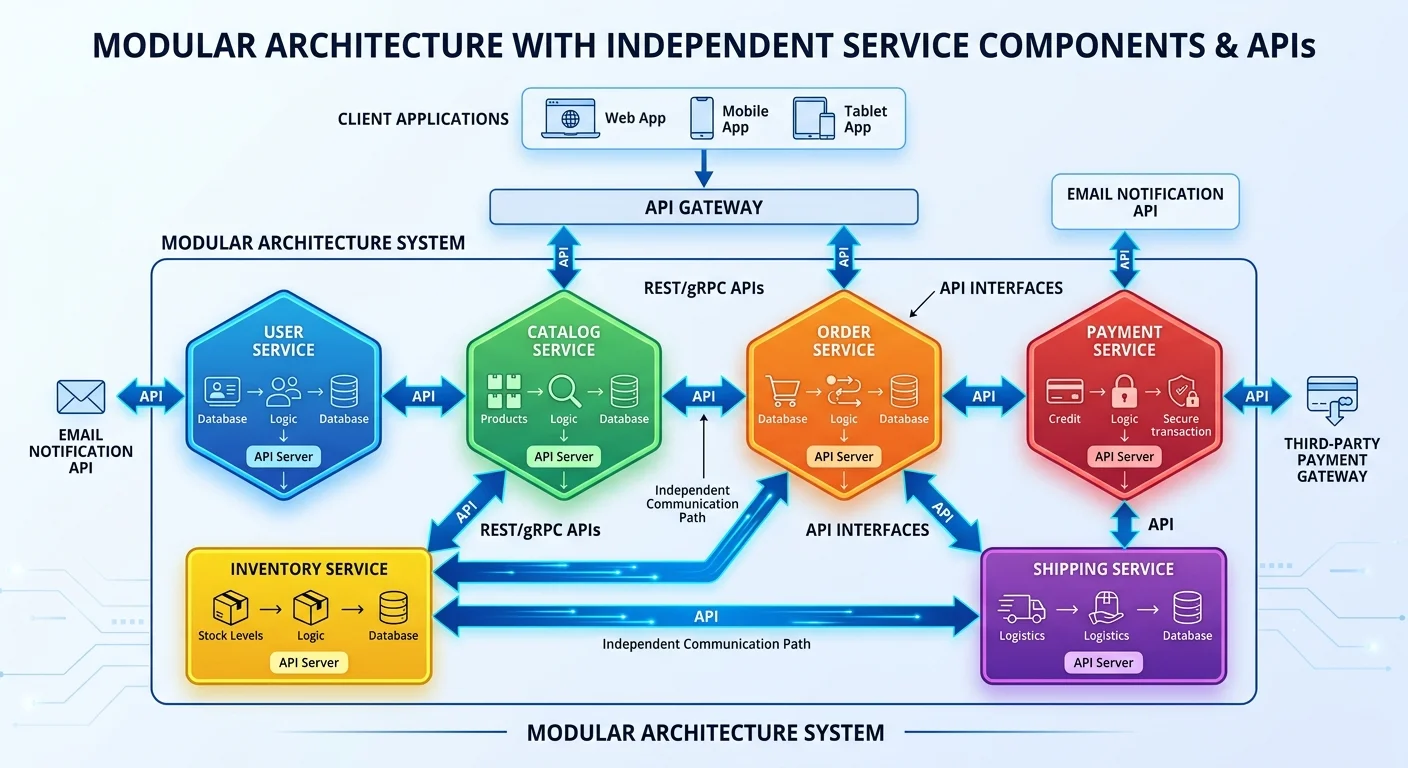
Step 1: Design Modular Architecture from Day One
Separation of Concerns in Practice
The foundation of scalable code is modular design. When each module handles one responsibility, you can scale individual pieces independently rather than scaling the entire application. Understanding how code optimization works in practice starts with recognizing that architecture decisions shape performance ceilings. A payment processing module, for instance, should know nothing about your notification system. They communicate through well-defined interfaces, not shared state.
Think about how Netflix decomposed its monolith into over 700 microservices. Each service owns its data, exposes a clean API, and can be deployed independently. You don't need to go that far, but the principle holds at every scale. Even within a single application, organizing code into distinct modules with clear boundaries makes it far easier to identify bottlenecks and scale the parts that need it most.
Read also Code Reuse Best Practices to Reduce Development Time
Start by mapping your domain into bounded contexts. An e-commerce application might have separate modules for inventory, ordering, user management, and shipping. Each module should have its own data access layer and business logic. When one module needs something from another, it requests it through an interface rather than reaching directly into the other's internals. This discipline pays enormous dividends as your codebase and team grow simultaneously.
Create an architectural decision record (ADR) for each major design choice so future team members understand why boundaries exist where they do.
Dependency Injection and Loose Coupling
Loose coupling is the mechanism that makes modularity real rather than theoretical. Dependency injection (DI) allows you to swap implementations without modifying consuming code. If your order service depends on an interface called IPaymentGateway rather than a concrete StripePaymentGateway class, you can switch providers, add load balancing, or introduce a mock for testing without touching business logic. Frameworks like Spring, ASP.NET Core, and NestJS provide built-in DI containers that make this pattern straightforward.
Loose coupling also enables independent scaling decisions. You might discover that your image processing module consumes ten times more CPU than your authentication module. With properly decoupled code, you can extract the image processor into its own service, allocate dedicated resources, and scale it horizontally. Tight coupling would force you to scale everything together, wasting resources and increasing deployment risk across the board.
Step 2: Optimize Data Structures and Algorithms for Scale
Choosing the Right Structure
Choosing optimal data structures is one of the most impactful optimization techniques available to any developer. A HashMap gives you O(1) average lookups, while a List requires O(n) scanning. At 100 records, the difference is negligible. At 10 million records, it's the difference between a 2ms response and a 30-second timeout. If you're exploring code optimization techniques as a starting point, data structure selection is where you'll see the fastest returns.
Consider real scenarios: if you need to frequently check membership in a collection, a HashSet outperforms a List by orders of magnitude. If you need sorted data with fast insertions, a balanced tree (like Java's TreeMap or C++'s std::map) is better than repeatedly sorting an array. When working with Java-based applications, understanding the Collections framework deeply can shape your system's performance ceiling from the start.
| Data Structure | Lookup Time | Insert Time | Best Use Case |
|---|---|---|---|
| HashMap | O(1) avg | O(1) avg | Key-value lookups, caching |
| ArrayList | O(1) index, O(n) search | O(1) amortized | Sequential access, iteration |
| TreeMap | O(log n) | O(log n) | Sorted key-value pairs |
| LinkedList | O(n) | O(1) at ends | Frequent insertions/deletions |
| HashSet | O(1) avg | O(1) avg | Membership testing, deduplication |
Caching Strategies That Actually Work
Caching is the single most effective way to improve performance at scale without rewriting business logic. The key is caching at the right layer. Application-level caching (in-memory stores like Redis or Memcached) works well for frequently accessed data that changes infrequently. Database query caching reduces load on your persistence layer. CDN caching handles static assets and even dynamic content at the edge, closer to your users.
The tricky part is cache invalidation. A stale cache can cause bugs that are extremely difficult to reproduce and diagnose. Use time-to-live (TTL) values appropriate to your data's change frequency. For more dynamic data, consider event-driven invalidation where writes publish events that trigger cache updates. Avoid caching everything blindly; focus on data that's read frequently and expensive to compute or fetch. This connection between clean code and software performance becomes clear when your caching logic is easy to understand and maintain.
Cache hit ratios below 80% often indicate poor cache key design or overly aggressive TTL settings. Monitor this metric actively.
Step 3: Write Stateless, Horizontally Scalable Code
Why Stateless Design Matters
Horizontal scaling means adding more instances of your application behind a load balancer. This only works if any instance can handle any request. The moment you store session data in local memory, file system state, or instance-specific caches, you've tied users to specific instances. That creates an affinity problem where losing one instance means losing all its users' sessions, and adding instances doesn't distribute load evenly.
Move all state to external stores. Sessions belong in Redis or a distributed cache. File uploads should go directly to object storage like S3, not local disk. Configuration should come from environment variables or a configuration service, not local files. Each application instance should be identical and disposable. If you can destroy any instance at any moment without losing data or breaking user experiences, you've achieved stateless design. This principle applies whether you're running containers, serverless functions, or traditional VMs.
"If you can destroy any instance at any moment without losing data, you've achieved stateless design."
Asynchronous Patterns and Queue-Based Processing
Not every operation needs to complete within the HTTP request-response cycle. Sending emails, generating reports, processing images, and syncing with third-party services are all excellent candidates for asynchronous processing. Message queues like RabbitMQ, Apache Kafka, or Amazon SQS let you decouple the request from the processing. The API accepts the request, publishes a message, and returns immediately. Worker processes consume messages at their own pace.
This pattern transforms your scalability profile dramatically. During traffic spikes, your queue absorbs the burst while workers process at a sustainable rate. You can scale workers independently based on queue depth. If image processing is backed up, add more image processing workers without touching anything else. The key is designing your messages to be idempotent, meaning processing the same message twice produces the same result. Network failures and retries are inevitable in distributed systems, and idempotency prevents duplicate side effects.
Error handling in async systems requires special attention. Dead letter queues capture messages that fail repeatedly, preventing them from blocking other work. Implement monitoring and alerting on queue depths and consumer lag so you can respond before backlogs become visible to users. Structured logging with correlation IDs lets you trace a request from the initial API call through multiple queue hops to final completion.
Never process financial transactions asynchronously without implementing exactly-once delivery semantics or compensating transactions for failures.
Step 4: Profile and Refactor Continuously
Always Profile Before You Optimize
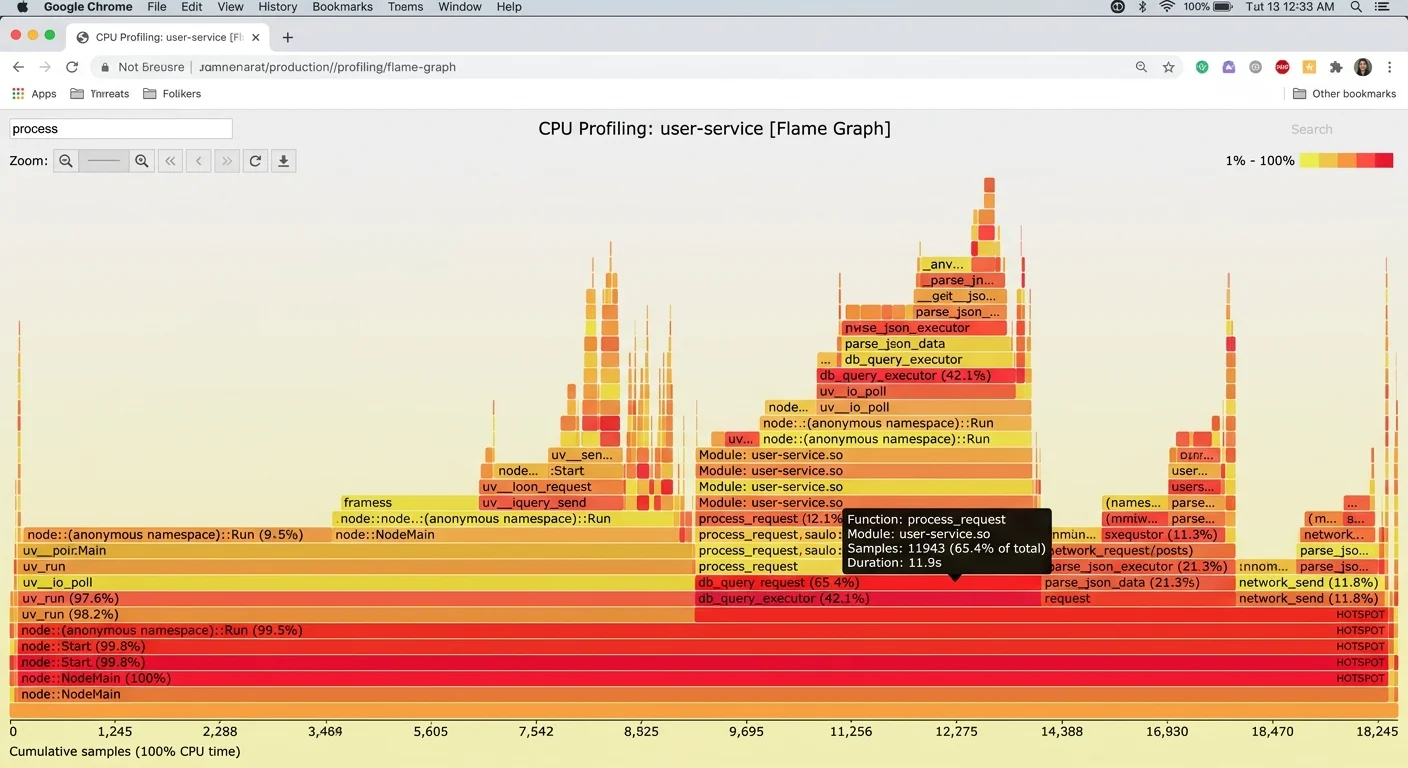
Developers routinely guess wrong about where their bottlenecks live. You might spend a week optimizing a function that accounts for 0.3% of total execution time while ignoring a database query that consumes 40%. Profiling tools eliminate guesswork. Use flame graphs (via tools like async-profiler for Java, py-spy for Python, or Chrome DevTools for JavaScript) to visualize where CPU time actually goes. Application Performance Monitoring (APM) tools like Datadog, New Relic, or open-source alternatives like Jaeger provide distributed tracing across services.
Understanding the difference between refactoring and optimization matters here. Optimization targets specific performance hotspots identified through profiling. Refactoring improves code structure and readability, which indirectly supports future optimization by making the codebase easier to reason about. Both are necessary, but they serve different purposes and should be approached with different mindsets and measurement criteria.
Set a performance budget for critical user flows. Measure against it in CI/CD so regressions are caught before deployment.
Refactoring for Growth
Technical debt is the silent killer of scalability. Code that's difficult to understand is code that's dangerous to change. When teams are afraid to modify critical paths because the logic is tangled and untested, they work around problems instead of solving them. These workarounds accumulate, creating increasingly fragile systems. Following practical refactoring tips to write cleaner code faster keeps your codebase in a state where scaling decisions can be implemented quickly and confidently.
Schedule refactoring as a regular activity, not a separate project that gets perpetually deprioritized. The "boy scout rule" (leave the code cleaner than you found it) works well at the individual level. At the team level, dedicate a consistent percentage of each sprint to addressing technical debt. Track it visibly alongside feature work. When refactoring, prioritize the modules that sit on your critical scaling path: the ones that handle the most traffic, process the most data, or change the most frequently.
Write comprehensive tests before refactoring. Unit tests verify individual functions behave correctly. Integration tests confirm modules work together. Load tests validate that your changes actually improve performance under realistic conditions. Without this safety net, refactoring becomes a gamble. With it, you can restructure aggressively, knowing that your test suite will catch regressions before they reach production. Automated testing transforms refactoring from a risky endeavor into a routine practice.
Frequently Asked Questions
?How do I start profiling before I know which code is the bottleneck?
?Is dependency injection worth the setup complexity for smaller projects?
?How long does refactoring for scalability typically add to a sprint?
?Does stateless design mean I can never store any session data server-side?
Final Thoughts
Building scalable code isn't a single technique; it's a collection of habits applied consistently across your development lifecycle. Start with modular architecture, choose your data structures deliberately, design for statelessness, and profile before you optimize. These four steps will carry most applications through significant growth without painful rewrites.
The investment in clean, well-structured software pays compound interest as your user base, your team, and your feature set expand. Scalability is built one thoughtful decision at a time, starting today.
Disclaimer: Portions of this content may have been generated using AI tools to enhance clarity and brevity. While reviewed by a human, independent verification is encouraged.


